CARL- Contextually Adaptive Reinforcement Learning¶
Welcome to the documentation of CARL, a benchmark library for Contextually Adaptive Reinforcement Learning. CARL extends well-known RL environments with context, making them easily configurable to test robustness and generalization.
Feel free to check out our paper and our blog post on CARL!
What is Context?¶
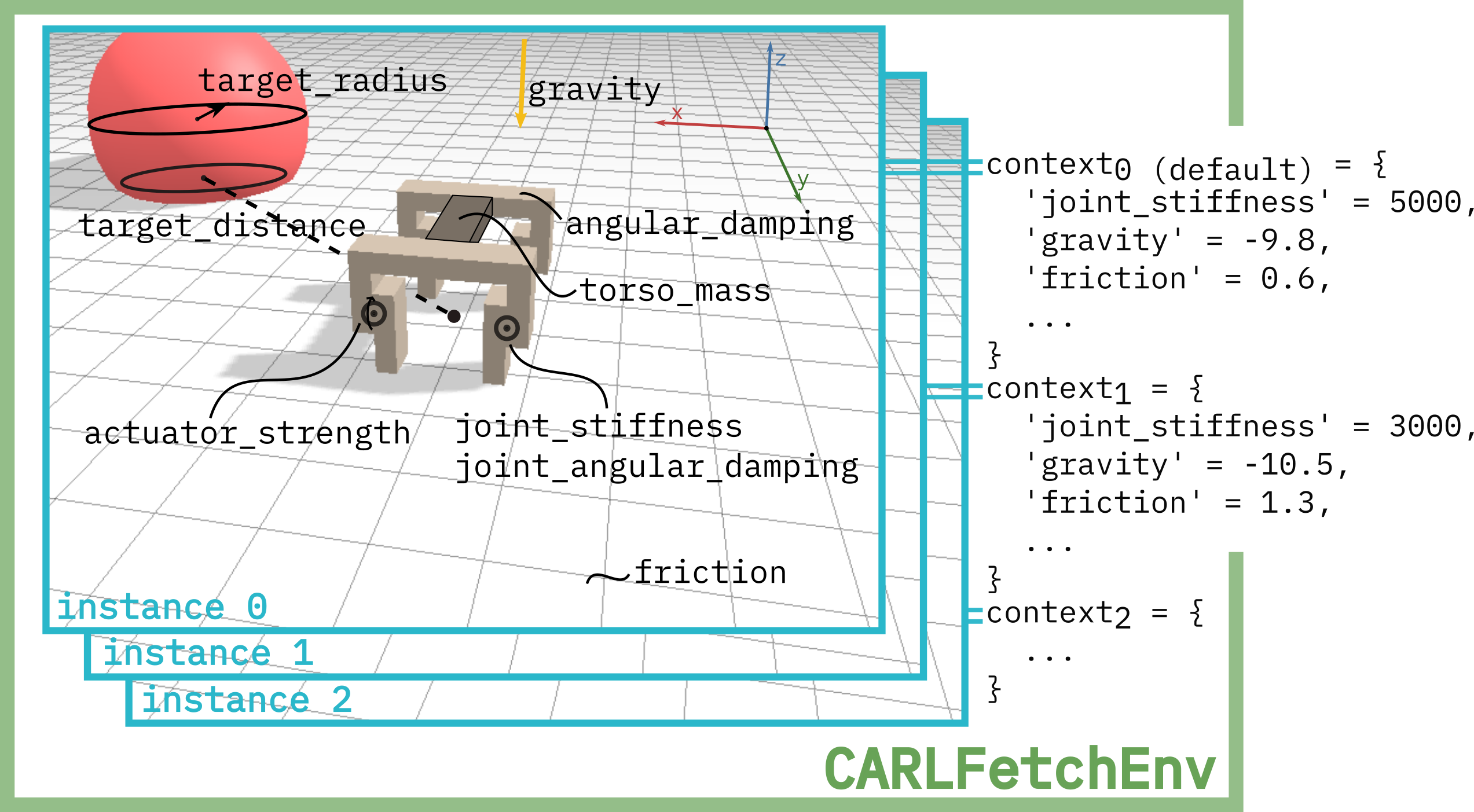
Context can change the goals and dynamics of an environment. The interaction interval in Pendulum, for example, can make that environment muhc easier or harder. The same is true for the composition of a Mario level. So context is a tool for creating variations in reinforcement learning environments. In contrast to other approaches like procedural generation, however, context can easily be defined and controlled by the user. That means you have full control over the difficulty and degree of variations in your environments. This way, you can gain detailed insights into the generalization capabilities of your agents - where do they excel and where do they fail? CARL can help you find the answer!
If you’re interested in learning more about context, check out our paper or context in RL or the corrsponding blog post.
What can you do with CARL?¶
With CARL, you can easily define train and test distributions across different features of your favorite environments. Examples include: - training on short CartPole poles and testing if the policy can transfer to longer ones - training LunarLander on moon gravity and seeing if it can also land on mars - training and testing on a uniform distribution of floor friction values on Halfcheetah … and many more!
Simply decide on a generalization task you want your agent to solve, choose the context feature(s) to vary and train your agent just like on any other gymnasium environment
Contact¶
CARL is developed by https://www.automl.org/. If you want to contribute or found an issue please visit our github page https://github.com/automl/CARL.