Note
Click here to download the full example code
ParEGO¶
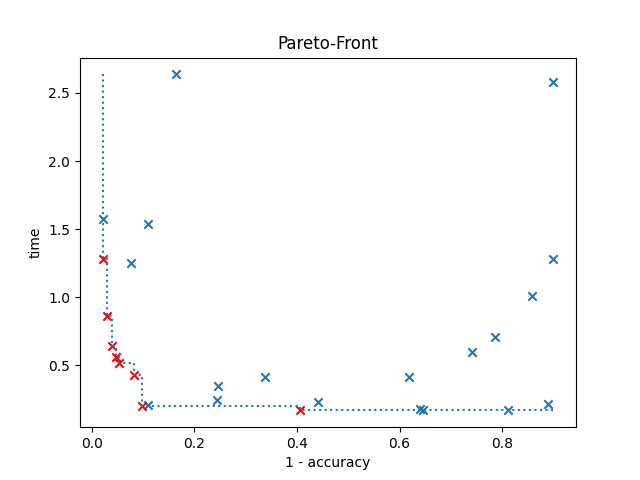
An example of how to use multi-objective optimization with ParEGO. Both accuracy and run-time are going to be optimized, and the configurations are shown in a plot, highlighting the best ones in a Pareto front. The red cross indicates the best configuration selected by SMAC.
In the optimization, SMAC evaluates the configurations on three different seeds. Therefore, the plot shows the mean accuracy and run-time of each configuration.
[WARNING][target_function_runner.py:71] The argument budget is not set by SMAC. Consider removing it.
[INFO][abstract_initial_design.py:133] Using 5 initial design and 0 additional configurations.
[INFO][intensifier.py:275] No incumbent provided in the first run. Sampling a new challenger...
[INFO][intensifier.py:446] First run and no incumbent provided. Challenger is assumed to be the incumbent.
[INFO][intensifier.py:566] Updated estimated cost of incumbent on 1 trials: 0.5752
[INFO][intensifier.py:566] Updated estimated cost of incumbent on 2 trials: 0.2876
[INFO][abstract_intensifier.py:340] Challenger (0.4872) is better than incumbent (0.5468) on 2 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- activation: 'logistic' -> 'tanh'
[INFO][abstract_intensifier.py:367] --- batch_size: None -> 77
[INFO][abstract_intensifier.py:367] --- learning_rate_init: None -> 0.000534923804864797
[INFO][abstract_intensifier.py:367] --- n_layer: 4 -> 1
[INFO][abstract_intensifier.py:367] --- n_neurons: 11 -> 146
[INFO][abstract_intensifier.py:367] --- solver: 'lbfgs' -> 'adam'
[INFO][abstract_intensifier.py:340] Challenger (0.3596) is better than incumbent (0.488) on 2 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- batch_size: 77 -> 200
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.000534923804864797 -> 0.001
[INFO][abstract_intensifier.py:367] --- n_neurons: 146 -> 10
[INFO][intensifier.py:566] Updated estimated cost of incumbent on 3 trials: 0.3885
[INFO][abstract_intensifier.py:340] Challenger (0.1216) is better than incumbent (0.4473) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- batch_size: 200 -> 51
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.001 -> 0.00817334776207205
[INFO][abstract_intensifier.py:367] --- n_neurons: 10 -> 196
[INFO][abstract_intensifier.py:340] Challenger (0.1244) is better than incumbent (0.2632) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- activation: 'tanh' -> 'logistic'
[INFO][abstract_intensifier.py:367] --- batch_size: 51 -> 165
[INFO][abstract_intensifier.py:367] --- learning_rate: None -> 'constant'
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.00817334776207205 -> 0.0006455320978369347
[INFO][abstract_intensifier.py:367] --- n_neurons: 196 -> 10
[INFO][abstract_intensifier.py:367] --- solver: 'adam' -> 'sgd'
[INFO][abstract_intensifier.py:340] Challenger (0.0984) is better than incumbent (0.1244) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- activation: 'logistic' -> 'tanh'
[INFO][abstract_intensifier.py:367] --- batch_size: 165 -> 200
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.0006455320978369347 -> 0.001
[INFO][abstract_intensifier.py:367] --- solver: 'sgd' -> 'adam'
[INFO][abstract_intensifier.py:340] Challenger (0.0977) is better than incumbent (0.1244) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- batch_size: 165 -> 164
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.0006455320978369347 -> 0.0014505860230242967
[INFO][abstract_intensifier.py:367] --- n_neurons: 10 -> 16
[INFO][abstract_intensifier.py:340] Challenger (0.0364) is better than incumbent (0.0977) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- batch_size: 164 -> 165
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.0014505860230242967 -> 0.7371961864257597
[INFO][abstract_intensifier.py:367] --- n_neurons: 16 -> 50
[INFO][abstract_intensifier.py:340] Challenger (0.099) is better than incumbent (0.2446) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- activation: 'logistic' -> 'tanh'
[INFO][abstract_intensifier.py:367] --- batch_size: 165 -> 84
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.7371961864257597 -> 0.0005355929478377824
[INFO][abstract_intensifier.py:367] --- n_layer: 1 -> 3
[INFO][abstract_intensifier.py:367] --- n_neurons: 50 -> 141
[INFO][abstract_intensifier.py:340] Challenger (0.0849) is better than incumbent (0.099) on 3 trials.
[INFO][abstract_intensifier.py:364] Changes in incumbent:
[INFO][abstract_intensifier.py:367] --- batch_size: 84 -> 153
[INFO][abstract_intensifier.py:367] --- learning_rate_init: 0.0005355929478377824 -> 0.031690463296719304
[INFO][abstract_intensifier.py:367] --- n_layer: 3 -> 1
[INFO][abstract_intensifier.py:367] --- n_neurons: 141 -> 15
[INFO][abstract_intensifier.py:367] --- solver: 'sgd' -> 'adam'
[INFO][base_smbo.py:260] Configuration budget is exhausted.
[INFO][abstract_facade.py:325] Final Incumbent: {'activation': 'tanh', 'n_layer': 1, 'n_neurons': 15, 'solver': 'adam', 'batch_size': 153, 'learning_rate_init': 0.031690463296719304}
[INFO][abstract_facade.py:326] Estimated cost: 0.07629433962048256
Default costs: [0.62956618 0.17092101]
Validated costs from the Pareto front:
[0.05082431 0.55831965]
[0.0369122 0.64362804]
[0.02985763 0.85785421]
[0.61418137 0.16880131]
[0.05397864 0.51068695]
[0.10146962 0.20230182]
[0.0179903 1.23766311]
[0.06770762 0.41083908]
from __future__ import annotations
import time
import warnings
import matplotlib.pyplot as plt
import numpy as np
from ConfigSpace import (
Categorical,
Configuration,
ConfigurationSpace,
EqualsCondition,
Float,
InCondition,
Integer,
)
from sklearn.datasets import load_digits
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.neural_network import MLPClassifier
from smac import HyperparameterOptimizationFacade as HPOFacade
from smac import Scenario
from smac.facade.abstract_facade import AbstractFacade
from smac.multi_objective.parego import ParEGO
__copyright__ = "Copyright 2021, AutoML.org Freiburg-Hannover"
__license__ = "3-clause BSD"
digits = load_digits()
class MLP:
@property
def configspace(self) -> ConfigurationSpace:
cs = ConfigurationSpace()
n_layer = Integer("n_layer", (1, 5), default=1)
n_neurons = Integer("n_neurons", (8, 256), log=True, default=10)
activation = Categorical("activation", ["logistic", "tanh", "relu"], default="tanh")
solver = Categorical("solver", ["lbfgs", "sgd", "adam"], default="adam")
batch_size = Integer("batch_size", (30, 300), default=200)
learning_rate = Categorical("learning_rate", ["constant", "invscaling", "adaptive"], default="constant")
learning_rate_init = Float("learning_rate_init", (0.0001, 1.0), default=0.001, log=True)
cs.add_hyperparameters([n_layer, n_neurons, activation, solver, batch_size, learning_rate, learning_rate_init])
use_lr = EqualsCondition(child=learning_rate, parent=solver, value="sgd")
use_lr_init = InCondition(child=learning_rate_init, parent=solver, values=["sgd", "adam"])
use_batch_size = InCondition(child=batch_size, parent=solver, values=["sgd", "adam"])
# We can also add multiple conditions on hyperparameters at once:
cs.add_conditions([use_lr, use_batch_size, use_lr_init])
return cs
def train(self, config: Configuration, seed: int = 0, budget: int = 10) -> dict[str, float]:
lr = config["learning_rate"] if config["learning_rate"] else "constant"
lr_init = config["learning_rate_init"] if config["learning_rate_init"] else 0.001
batch_size = config["batch_size"] if config["batch_size"] else 200
start_time = time.time()
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
classifier = MLPClassifier(
hidden_layer_sizes=[config["n_neurons"]] * config["n_layer"],
solver=config["solver"],
batch_size=batch_size,
activation=config["activation"],
learning_rate=lr,
learning_rate_init=lr_init,
max_iter=int(np.ceil(budget)),
random_state=seed,
)
# Returns the 5-fold cross validation accuracy
cv = StratifiedKFold(n_splits=5, random_state=seed, shuffle=True) # to make CV splits consistent
score = cross_val_score(classifier, digits.data, digits.target, cv=cv, error_score="raise")
return {
"1 - accuracy": 1 - np.mean(score),
"time": time.time() - start_time,
}
def plot_pareto(smac: AbstractFacade) -> None:
"""Plots configurations from SMAC and highlights the best configurations in a Pareto front."""
# Get Pareto costs
_, c = smac.runhistory.get_pareto_front()
pareto_costs = np.array(c)
# Sort them a bit
pareto_costs = pareto_costs[pareto_costs[:, 0].argsort()]
# Get all other costs from runhistory
average_costs = []
for config in smac.runhistory.get_configs():
# Since we use multiple seeds, we have to average them to get only one cost value pair for each configuration
average_cost = smac.runhistory.average_cost(config)
if average_cost not in c:
average_costs += [average_cost]
# Let's work with a numpy array
costs = np.vstack(average_costs)
costs_x, costs_y = costs[:, 0], costs[:, 1]
pareto_costs_x, pareto_costs_y = pareto_costs[:, 0], pareto_costs[:, 1]
plt.scatter(costs_x, costs_y, marker="x")
plt.scatter(pareto_costs_x, pareto_costs_y, marker="x", c="r")
plt.step(
[pareto_costs_x[0]] + pareto_costs_x.tolist() + [np.max(costs_x)], # We add bounds
[np.max(costs_y)] + pareto_costs_y.tolist() + [np.min(pareto_costs_y)], # We add bounds
where="post",
linestyle=":",
)
plt.title("Pareto-Front")
plt.xlabel(smac.scenario.objectives[0])
plt.ylabel(smac.scenario.objectives[1])
plt.show()
if __name__ == "__main__":
mlp = MLP()
# Define our environment variables
scenario = Scenario(
mlp.configspace,
objectives=["1 - accuracy", "time"],
walltime_limit=40, # After 40 seconds, we stop the hyperparameter optimization
n_trials=200, # Evaluate max 200 different trials
n_workers=1,
)
# We want to run five random configurations before starting the optimization.
initial_design = HPOFacade.get_initial_design(scenario, n_configs=5)
multi_objective_algorithm = ParEGO(scenario)
# Create our SMAC object and pass the scenario and the train method
smac = HPOFacade(
scenario,
mlp.train,
initial_design=initial_design,
multi_objective_algorithm=multi_objective_algorithm,
overwrite=True,
)
# Let's optimize
# Keep in mind: The incumbent is ambiguous here because of ParEGO
smac.optimize()
# Get cost of default configuration
default_cost = smac.validate(mlp.configspace.get_default_configuration())
print(f"Default costs: {default_cost}\n")
print("Validated costs from the Pareto front:")
for i, config in enumerate(smac.runhistory.get_pareto_front()[0]):
cost = smac.validate(config)
print(cost)
# Let's plot a pareto front
plot_pareto(smac)
Total running time of the script: ( 0 minutes 54.620 seconds)