Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Multi-Layer Perceptron Using Multiple Epochs¶
Example for optimizing a Multi-Layer Perceptron (MLP) using multiple budgets.
Since we want to take advantage of multi-fidelity, the MultiFidelityFacade is a good choice. By default,
MultiFidelityFacade internally runs with hyperband as
intensification, which is a combination of an aggressive racing mechanism and Successive Halving. Crucially, the target
function must accept a budget variable, detailing how much fidelity smac wants to allocate to this
configuration. In this example, we use both SuccessiveHalving and Hyperband to compare the results.
MLP is a deep neural network, and therefore, we choose epochs as fidelity type. This implies,
that budget specifies the number of epochs smac wants to allocate. The digits dataset
is chosen to optimize the average accuracy on 5-fold cross validation.
Note
This example uses the MultiFidelityFacade facade, which is the closest implementation to
BOHB.
[INFO][abstract_facade.py:203] Workers are reduced to 8.
[INFO][abstract_initial_design.py:147] Using 5 initial design configurations and 0 additional configurations.
[INFO][successive_halving.py:164] Successive Halving uses budget type BUDGETS with eta 3, min budget 1, and max budget 25.
[INFO][successive_halving.py:323] Number of configs in stage:
[INFO][successive_halving.py:325] --- Bracket 0: [9, 3, 1]
[INFO][successive_halving.py:327] Budgets in stage:
[INFO][successive_halving.py:329] --- Bracket 0: [2.7777777777777777, 8.333333333333332, 25.0]
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 150 trials.
[INFO][smbo.py:328] Configuration budget is exhausted:
[INFO][smbo.py:329] --- Remaining wallclock time: -1.2250981330871582
[INFO][smbo.py:330] --- Remaining cpu time: inf
[INFO][smbo.py:331] --- Remaining trials: 175
Default cost (SuccessiveHalving): 0.36672856700711853
Incumbent cost (SuccessiveHalving): inf
[INFO][abstract_initial_design.py:82] Using `n_configs` and ignoring `n_configs_per_hyperparameter`.
[INFO][abstract_facade.py:203] Workers are reduced to 8.
/opt/hostedtoolcache/Python/3.10.14/x64/lib/python3.10/site-packages/distributed/node.py:182: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 39477 instead
warnings.warn(
[INFO][abstract_initial_design.py:147] Using 5 initial design configurations and 0 additional configurations.
[INFO][successive_halving.py:164] Successive Halving uses budget type BUDGETS with eta 3, min budget 1, and max budget 25.
[INFO][successive_halving.py:323] Number of configs in stage:
[INFO][successive_halving.py:325] --- Bracket 0: [9, 3, 1]
[INFO][successive_halving.py:325] --- Bracket 1: [5, 1]
[INFO][successive_halving.py:325] --- Bracket 2: [3]
[INFO][successive_halving.py:327] Budgets in stage:
[INFO][successive_halving.py:329] --- Bracket 0: [2.7777777777777777, 8.333333333333332, 25.0]
[INFO][successive_halving.py:329] --- Bracket 1: [8.333333333333332, 25.0]
[INFO][successive_halving.py:329] --- Bracket 2: [25.0]
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][smbo.py:320] Finished 0 trials.
[INFO][abstract_intensifier.py:516] Added config 6ad6db as new incumbent because there are no incumbents yet.
[INFO][abstract_intensifier.py:595] Added config 00a2dc and rejected config 6ad6db as incumbent because it is not better than the incumbents on 1 instances:
[INFO][smbo.py:320] Finished 50 trials.
[INFO][smbo.py:320] Finished 50 trials.
[INFO][smbo.py:320] Finished 100 trials.
[INFO][smbo.py:320] Finished 150 trials.
[INFO][abstract_intensifier.py:595] Added config 711e78 and rejected config 00a2dc as incumbent because it is not better than the incumbents on 1 instances:
[INFO][smbo.py:328] Configuration budget is exhausted:
[INFO][smbo.py:329] --- Remaining wallclock time: -1.718996524810791
[INFO][smbo.py:330] --- Remaining cpu time: inf
[INFO][smbo.py:331] --- Remaining trials: 165
Default cost (Hyperband): 0.36672856700711853
Incumbent cost (Hyperband): 0.02560352831940571
import warnings
import matplotlib.pyplot as plt
import numpy as np
from ConfigSpace import (
Categorical,
Configuration,
ConfigurationSpace,
EqualsCondition,
Float,
InCondition,
Integer,
)
from sklearn.datasets import load_digits
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.neural_network import MLPClassifier
from smac import MultiFidelityFacade as MFFacade
from smac import Scenario
from smac.facade import AbstractFacade
from smac.intensifier.hyperband import Hyperband
from smac.intensifier.successive_halving import SuccessiveHalving
__copyright__ = "Copyright 2021, AutoML.org Freiburg-Hannover"
__license__ = "3-clause BSD"
dataset = load_digits()
class MLP:
@property
def configspace(self) -> ConfigurationSpace:
# Build Configuration Space which defines all parameters and their ranges.
# To illustrate different parameter types, we use continuous, integer and categorical parameters.
cs = ConfigurationSpace()
n_layer = Integer("n_layer", (1, 5), default=1)
n_neurons = Integer("n_neurons", (8, 256), log=True, default=10)
activation = Categorical("activation", ["logistic", "tanh", "relu"], default="tanh")
solver = Categorical("solver", ["lbfgs", "sgd", "adam"], default="adam")
batch_size = Integer("batch_size", (30, 300), default=200)
learning_rate = Categorical("learning_rate", ["constant", "invscaling", "adaptive"], default="constant")
learning_rate_init = Float("learning_rate_init", (0.0001, 1.0), default=0.001, log=True)
# Add all hyperparameters at once:
cs.add([n_layer, n_neurons, activation, solver, batch_size, learning_rate, learning_rate_init])
# Adding conditions to restrict the hyperparameter space...
# ... since learning rate is only used when solver is 'sgd'.
use_lr = EqualsCondition(child=learning_rate, parent=solver, value="sgd")
# ... since learning rate initialization will only be accounted for when using 'sgd' or 'adam'.
use_lr_init = InCondition(child=learning_rate_init, parent=solver, values=["sgd", "adam"])
# ... since batch size will not be considered when optimizer is 'lbfgs'.
use_batch_size = InCondition(child=batch_size, parent=solver, values=["sgd", "adam"])
# We can also add multiple conditions on hyperparameters at once:
cs.add([use_lr, use_batch_size, use_lr_init])
return cs
def train(self, config: Configuration, seed: int = 0, budget: int = 25) -> float:
# For deactivated parameters (by virtue of the conditions),
# the configuration stores None-values.
# This is not accepted by the MLP, so we replace them with placeholder values.
lr = config.get("learning_rate", "constant")
lr_init = config.get("learning_rate_init", 0.001)
batch_size = config.get("batch_size", 200)
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
classifier = MLPClassifier(
hidden_layer_sizes=[config["n_neurons"]] * config["n_layer"],
solver=config["solver"],
batch_size=batch_size,
activation=config["activation"],
learning_rate=lr,
learning_rate_init=lr_init,
max_iter=int(np.ceil(budget)),
random_state=seed,
)
# Returns the 5-fold cross validation accuracy
cv = StratifiedKFold(n_splits=5, random_state=seed, shuffle=True) # to make CV splits consistent
score = cross_val_score(classifier, dataset.data, dataset.target, cv=cv, error_score="raise")
return 1 - np.mean(score)
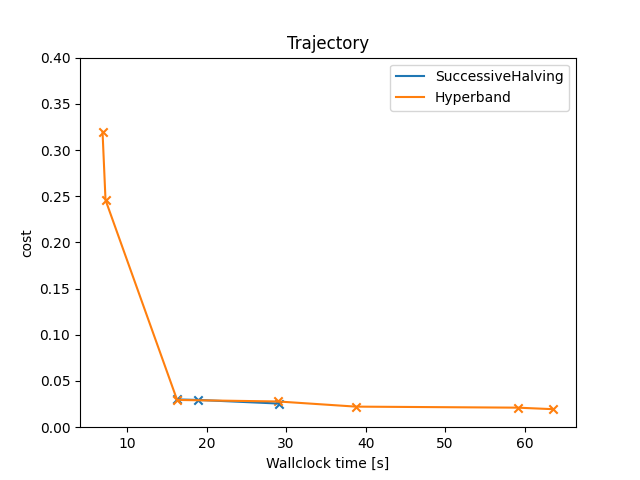
def plot_trajectory(facades: list[AbstractFacade]) -> None:
"""Plots the trajectory (incumbents) of the optimization process."""
plt.figure()
plt.title("Trajectory")
plt.xlabel("Wallclock time [s]")
plt.ylabel(facades[0].scenario.objectives)
plt.ylim(0, 0.4)
for facade in facades:
X, Y = [], []
for item in facade.intensifier.trajectory:
# Single-objective optimization
assert len(item.config_ids) == 1
assert len(item.costs) == 1
y = item.costs[0]
x = item.walltime
X.append(x)
Y.append(y)
plt.plot(X, Y, label=facade.intensifier.__class__.__name__)
plt.scatter(X, Y, marker="x")
plt.legend()
plt.show()
if __name__ == "__main__":
mlp = MLP()
facades: list[AbstractFacade] = []
for intensifier_object in [SuccessiveHalving, Hyperband]:
# Define our environment variables
scenario = Scenario(
mlp.configspace,
walltime_limit=60, # After 60 seconds, we stop the hyperparameter optimization
n_trials=500, # Evaluate max 500 different trials
min_budget=1, # Train the MLP using a hyperparameter configuration for at least 5 epochs
max_budget=25, # Train the MLP using a hyperparameter configuration for at most 25 epochs
n_workers=8,
)
# We want to run five random configurations before starting the optimization.
initial_design = MFFacade.get_initial_design(scenario, n_configs=5)
# Create our intensifier
intensifier = intensifier_object(scenario, incumbent_selection="highest_budget")
# Create our SMAC object and pass the scenario and the train method
smac = MFFacade(
scenario,
mlp.train,
initial_design=initial_design,
intensifier=intensifier,
overwrite=True,
)
# Let's optimize
incumbent = smac.optimize()
# Get cost of default configuration
default_cost = smac.validate(mlp.configspace.get_default_configuration())
print(f"Default cost ({intensifier.__class__.__name__}): {default_cost}")
# Let's calculate the cost of the incumbent
incumbent_cost = smac.validate(incumbent)
print(f"Incumbent cost ({intensifier.__class__.__name__}): {incumbent_cost}")
facades.append(smac)
# Let's plot it
plot_trajectory(facades)
Total running time of the script: (2 minutes 13.214 seconds)