
Note
Click here to download the full example code or to run this example in your browser via Binder
Classification¶
The following example shows how to fit auto-sklearn to optimize for two competing metrics: precision and recall (read more on this tradeoff in the scikit-learn docs.
Auto-sklearn uses SMAC3’s implementation of ParEGO. Multi-objective ensembling and proper access to the full Pareto set will be added in the near future.
from pprint import pprint
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets
import sklearn.metrics
import autosklearn.classification
import autosklearn.metrics
Data Loading¶
X, y = sklearn.datasets.fetch_openml(data_id=31, return_X_y=True, as_frame=True)
# Change the target to align with scikit-learn's convention that
# ``1`` is the minority class. In this example it is predicting
# that a credit is "bad", i.e. that it will default.
y = np.array([1 if val == "bad" else 0 for val in y])
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
X, y, random_state=1
)
Build and fit a classifier¶
automl = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=120,
metric=[autosklearn.metrics.precision, autosklearn.metrics.recall],
delete_tmp_folder_after_terminate=False,
)
automl.fit(X_train, y_train, dataset_name="German Credit")
Fitting to the training data: 0%| | 0/120 [00:00<?, ?it/s, The total time budget for this task is 0:02:00]
Fitting to the training data: 1%| | 1/120 [00:01<01:59, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 2%|1 | 2/120 [00:02<01:58, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 2%|2 | 3/120 [00:03<01:57, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 3%|3 | 4/120 [00:04<01:56, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 4%|4 | 5/120 [00:05<01:55, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 5%|5 | 6/120 [00:06<01:54, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 6%|5 | 7/120 [00:07<01:53, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 7%|6 | 8/120 [00:08<01:52, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 8%|7 | 9/120 [00:09<01:51, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 8%|8 | 10/120 [00:10<01:50, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 9%|9 | 11/120 [00:11<01:49, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 10%|# | 12/120 [00:12<01:48, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 11%|# | 13/120 [00:13<01:47, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 12%|#1 | 14/120 [00:14<01:46, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 12%|#2 | 15/120 [00:15<01:45, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 13%|#3 | 16/120 [00:16<01:44, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 14%|#4 | 17/120 [00:17<01:43, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 15%|#5 | 18/120 [00:18<01:42, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 16%|#5 | 19/120 [00:19<01:41, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 17%|#6 | 20/120 [00:20<01:40, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 18%|#7 | 21/120 [00:21<01:39, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 18%|#8 | 22/120 [00:22<01:38, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 19%|#9 | 23/120 [00:23<01:37, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 20%|## | 24/120 [00:24<01:36, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 21%|## | 25/120 [00:25<01:35, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 22%|##1 | 26/120 [00:26<01:34, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 22%|##2 | 27/120 [00:27<01:33, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 23%|##3 | 28/120 [00:28<01:32, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 24%|##4 | 29/120 [00:29<01:31, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 25%|##5 | 30/120 [00:30<01:30, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 26%|##5 | 31/120 [00:31<01:29, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 27%|##6 | 32/120 [00:32<01:28, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 28%|##7 | 33/120 [00:33<01:27, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 28%|##8 | 34/120 [00:34<01:26, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 29%|##9 | 35/120 [00:35<01:25, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 30%|### | 36/120 [00:36<01:24, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 31%|### | 37/120 [00:37<01:23, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 32%|###1 | 38/120 [00:38<01:22, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 32%|###2 | 39/120 [00:39<01:21, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 33%|###3 | 40/120 [00:40<01:20, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 34%|###4 | 41/120 [00:41<01:19, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 35%|###5 | 42/120 [00:42<01:18, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 36%|###5 | 43/120 [00:43<01:17, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 37%|###6 | 44/120 [00:44<01:16, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 38%|###7 | 45/120 [00:45<01:15, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 38%|###8 | 46/120 [00:46<01:14, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 39%|###9 | 47/120 [00:47<01:13, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 40%|#### | 48/120 [00:48<01:12, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 41%|#### | 49/120 [00:49<01:11, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 42%|####1 | 50/120 [00:50<01:10, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 42%|####2 | 51/120 [00:51<01:09, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 43%|####3 | 52/120 [00:52<01:08, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 44%|####4 | 53/120 [00:53<01:07, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 45%|####5 | 54/120 [00:54<01:06, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 46%|####5 | 55/120 [00:55<01:05, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 47%|####6 | 56/120 [00:56<01:04, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 48%|####7 | 57/120 [00:57<01:03, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 48%|####8 | 58/120 [00:58<01:02, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 49%|####9 | 59/120 [00:59<01:01, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 50%|##### | 60/120 [01:00<01:00, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 51%|##### | 61/120 [01:01<00:59, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 52%|#####1 | 62/120 [01:02<00:58, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 52%|#####2 | 63/120 [01:03<00:57, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 53%|#####3 | 64/120 [01:04<00:56, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 54%|#####4 | 65/120 [01:05<00:55, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 55%|#####5 | 66/120 [01:06<00:54, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 56%|#####5 | 67/120 [01:07<00:53, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 57%|#####6 | 68/120 [01:08<00:52, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 57%|#####7 | 69/120 [01:09<00:51, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 58%|#####8 | 70/120 [01:10<00:50, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 59%|#####9 | 71/120 [01:11<00:49, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 60%|###### | 72/120 [01:12<00:48, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 61%|###### | 73/120 [01:13<00:47, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 62%|######1 | 74/120 [01:14<00:46, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 62%|######2 | 75/120 [01:15<00:45, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 63%|######3 | 76/120 [01:16<00:44, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 64%|######4 | 77/120 [01:17<00:43, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 65%|######5 | 78/120 [01:18<00:42, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 66%|######5 | 79/120 [01:19<00:41, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 67%|######6 | 80/120 [01:20<00:40, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 68%|######7 | 81/120 [01:21<00:39, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 68%|######8 | 82/120 [01:22<00:38, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 69%|######9 | 83/120 [01:23<00:37, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 70%|####### | 84/120 [01:24<00:36, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 71%|####### | 85/120 [01:25<00:35, 1.02s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 72%|#######1 | 86/120 [01:26<00:34, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 72%|#######2 | 87/120 [01:27<00:33, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 73%|#######3 | 88/120 [01:28<00:32, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 74%|#######4 | 89/120 [01:29<00:31, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 75%|#######5 | 90/120 [01:30<00:30, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 76%|#######5 | 91/120 [01:31<00:29, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 77%|#######6 | 92/120 [01:32<00:28, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 78%|#######7 | 93/120 [01:33<00:27, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 78%|#######8 | 94/120 [01:34<00:26, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 79%|#######9 | 95/120 [01:35<00:25, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 80%|######## | 96/120 [01:36<00:24, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 81%|######## | 97/120 [01:37<00:23, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 82%|########1 | 98/120 [01:38<00:22, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 82%|########2 | 99/120 [01:39<00:21, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 83%|########3 | 100/120 [01:40<00:20, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 84%|########4 | 101/120 [01:41<00:19, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 85%|########5 | 102/120 [01:42<00:18, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 86%|########5 | 103/120 [01:43<00:17, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 87%|########6 | 104/120 [01:44<00:16, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 88%|########7 | 105/120 [01:45<00:15, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 88%|########8 | 106/120 [01:46<00:14, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 89%|########9 | 107/120 [01:47<00:13, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 90%|######### | 108/120 [01:48<00:12, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 91%|######### | 109/120 [01:49<00:11, 1.00s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 92%|#########1| 110/120 [01:50<00:10, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 92%|#########2| 111/120 [01:51<00:09, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 93%|#########3| 112/120 [01:52<00:08, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 94%|#########4| 113/120 [01:53<00:07, 1.01s/it, The total time budget for this task is 0:02:00]
Fitting to the training data: 100%|##########| 120/120 [01:53<00:00, 1.06it/s, The total time budget for this task is 0:02:00]
AutoSklearnClassifier(delete_tmp_folder_after_terminate=False,
ensemble_class=<class 'autosklearn.ensembles.multiobjective_dummy_ensemble.MultiObjectiveDummyEnsemble'>,
metric=[precision, recall], per_run_time_limit=12,
time_left_for_this_task=120)
Compute the two competing metrics¶
predictions = automl.predict(X_test)
print("Precision", sklearn.metrics.precision_score(y_test, predictions))
print("Recall", sklearn.metrics.recall_score(y_test, predictions))
Precision 0.6060606060606061
Recall 0.2702702702702703
View the models found by auto-sklearn¶
They are by default sorted by the first metric given to auto-sklearn.
print(automl.leaderboard())
rank ensemble_weight type cost_0 cost_1 duration
model_id
21 1 1.0 random_forest 0.205128 0.586667 2.26745
cv_results also contains both metrics¶
Similarly to the leaderboard, they are sorted by the first metric given to auto-sklearn.
pprint(automl.cv_results_)
{'budgets': [0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0],
'mean_fit_time': array([ 2.39643669, 2.36486745, 2.11222196, 2.35924792, 2.99224687,
3.99693394, 2.25170207, 1.33412337, 2.26138425, 12.01665878,
1.5633893 , 2.20981121, 1.71976376, 0.95089316, 2.32155037,
1.12820411, 5.25267005, 1.3863163 , 11.49182248, 2.26745009,
2.02650976, 0.91681528, 2.18118858, 1.19276667, 1.87678552,
2.42130995, 1.0960691 , 2.74251366]),
'mean_test_precision': array([0.68888889, 0.61403509, 0.42156863, 0.55072464, 0.48275862,
0.70588235, 0.67391304, 0.38235294, 0.51401869, 0. ,
0.49090909, 0.55263158, 0.50526316, 0.59016393, 0.625 ,
0. , 0.47222222, 0.47272727, 0.54117647, 0.79487179,
0.44444444, 0. , 0.39534884, 0. , 0.51376147,
0.48148148, 0.34782609, 0.57534247]),
'mean_test_recall': array([0.41333333, 0.46666667, 0.57333333, 0.50666667, 0.18666667,
0.48 , 0.41333333, 0.17333333, 0.73333333, 0. ,
0.72 , 0.28 , 0.64 , 0.48 , 0.06666667,
0. , 0.45333333, 0.34666667, 0.61333333, 0.41333333,
0.69333333, 0. , 0.22666667, 0. , 0.74666667,
0.69333333, 0.53333333, 0.56 ]),
'param_balancing:strategy': masked_array(data=['none', 'none', 'weighting', 'weighting', 'weighting',
'weighting', 'none', 'weighting', 'weighting',
'weighting', 'weighting', 'none', 'weighting', 'none',
'none', 'weighting', 'weighting', 'none', 'weighting',
'none', 'weighting', 'none', 'none', 'weighting',
'weighting', 'weighting', 'weighting', 'weighting'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U9'),
'param_classifier:__choice__': masked_array(data=['random_forest', 'extra_trees', 'extra_trees',
'gradient_boosting', 'random_forest', 'mlp',
'random_forest', 'passive_aggressive', 'random_forest',
'libsvm_svc', 'gradient_boosting', 'mlp',
'gradient_boosting', 'sgd', 'extra_trees', 'lda',
'extra_trees', 'mlp', 'gradient_boosting',
'random_forest', 'adaboost', 'passive_aggressive',
'random_forest', 'bernoulli_nb', 'gradient_boosting',
'random_forest', 'sgd', 'random_forest'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U18'),
'param_classifier:adaboost:algorithm': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, 'SAMME', --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, False, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:adaboost:learning_rate': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, 0.2844845910527844, --, --, --,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, False, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:adaboost:max_depth': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, 2.0, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, False, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:adaboost:n_estimators': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, 370.0, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, False, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:bernoulli_nb:alpha': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, 39.87397441278958,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False,
True, True, True, True],
fill_value=1e+20),
'param_classifier:bernoulli_nb:fit_prior': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, 'False', --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:decision_tree:criterion': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:max_depth_factor': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:max_features': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:max_leaf_nodes': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:min_impurity_decrease': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:min_samples_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:min_samples_split': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:decision_tree:min_weight_fraction_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:extra_trees:bootstrap': masked_array(data=[--, 'True', 'False', --, --, --, --, --, --, --, --,
--, --, --, 'True', --, 'False', --, --, --, --, --,
--, --, --, --, --, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:extra_trees:criterion': masked_array(data=[--, 'entropy', 'entropy', --, --, --, --, --, --, --,
--, --, --, --, 'entropy', --, 'entropy', --, --, --,
--, --, --, --, --, --, --, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:extra_trees:max_depth': masked_array(data=[--, 'None', 'None', --, --, --, --, --, --, --, --, --,
--, --, 'None', --, 'None', --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:extra_trees:max_features': masked_array(data=[--, 0.5, 0.7655092431692035, --, --, --, --, --, --,
--, --, --, --, --, 0.15687109796165688, --,
0.993803313878608, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:extra_trees:max_leaf_nodes': masked_array(data=[--, 'None', 'None', --, --, --, --, --, --, --, --, --,
--, --, 'None', --, 'None', --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:extra_trees:min_impurity_decrease': masked_array(data=[--, 0.0, 0.0, --, --, --, --, --, --, --, --, --, --,
--, 0.0, --, 0.0, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:extra_trees:min_samples_leaf': masked_array(data=[--, 1.0, 19.0, --, --, --, --, --, --, --, --, --, --,
--, 3.0, --, 2.0, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:extra_trees:min_samples_split': masked_array(data=[--, 2.0, 5.0, --, --, --, --, --, --, --, --, --, --,
--, 13.0, --, 20.0, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:extra_trees:min_weight_fraction_leaf': masked_array(data=[--, 0.0, 0.0, --, --, --, --, --, --, --, --, --, --,
--, 0.0, --, 0.0, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, False, False, True, True, True, True, True,
True, True, True, True, True, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:early_stop': masked_array(data=[--, --, --, 'train', --, --, --, --, --, --, 'train',
--, 'off', --, --, --, --, --, 'train', --, --, --, --,
--, 'train', --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:gradient_boosting:l2_regularization': masked_array(data=[--, --, --, 3.387912939529945e-10, --, --, --, --, --,
--, 0.20982857192812085, --, 5.195231690836764e-09, --,
--, --, --, --, 0.05488841601458162, --, --, --, --,
--, 0.22864775632104425, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:learning_rate': masked_array(data=[--, --, --, 0.30755227194768237, --, --, --, --, --,
--, 0.012770531206809599, --, 0.06101786517649655, --,
--, --, --, --, 0.0843846716858782, --, --, --, --, --,
0.012770531206809599, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:loss': masked_array(data=[--, --, --, 'auto', --, --, --, --, --, --, 'auto', --,
'auto', --, --, --, --, --, 'auto', --, --, --, --, --,
'auto', --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:gradient_boosting:max_bins': masked_array(data=[--, --, --, 255.0, --, --, --, --, --, --, 255.0, --,
255.0, --, --, --, --, --, 255.0, --, --, --, --, --,
255.0, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:max_depth': masked_array(data=[--, --, --, 'None', --, --, --, --, --, --, 'None', --,
'None', --, --, --, --, --, 'None', --, --, --, --, --,
'None', --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:gradient_boosting:max_leaf_nodes': masked_array(data=[--, --, --, 60.0, --, --, --, --, --, --, 32.0, --,
10.0, --, --, --, --, --, 4.0, --, --, --, --, --,
41.0, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:min_samples_leaf': masked_array(data=[--, --, --, 39.0, --, --, --, --, --, --, 69.0, --,
22.0, --, --, --, --, --, 3.0, --, --, --, --, --,
55.0, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:n_iter_no_change': masked_array(data=[--, --, --, 18.0, --, --, --, --, --, --, 19.0, --, --,
--, --, --, --, --, 16.0, --, --, --, --, --, 10.0, --,
--, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, True, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:scoring': masked_array(data=[--, --, --, 'loss', --, --, --, --, --, --, 'loss', --,
'loss', --, --, --, --, --, 'loss', --, --, --, --, --,
'loss', --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:gradient_boosting:tol': masked_array(data=[--, --, --, 1e-07, --, --, --, --, --, --, 1e-07, --,
1e-07, --, --, --, --, --, 1e-07, --, --, --, --, --,
1e-07, --, --, --],
mask=[ True, True, True, False, True, True, True, True,
True, True, False, True, False, True, True, True,
True, True, False, True, True, True, True, True,
False, True, True, True],
fill_value=1e+20),
'param_classifier:gradient_boosting:validation_fraction': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:k_nearest_neighbors:n_neighbors': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:k_nearest_neighbors:p': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:k_nearest_neighbors:weights': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:lda:shrinkage': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, 'auto', --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:lda:shrinkage_factor': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:lda:tol': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, 0.06502391592449622, --, --, --, --, --, --, --,
--, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:liblinear_svc:C': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:dual': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:fit_intercept': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:intercept_scaling': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:loss': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:multi_class': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:penalty': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:liblinear_svc:tol': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:libsvm_svc:C': masked_array(data=[--, --, --, --, --, --, --, --, --, 2176.2897327948685,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:libsvm_svc:coef0': masked_array(data=[--, --, --, --, --, --, --, --, --,
-0.018575725453357728, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:libsvm_svc:degree': masked_array(data=[--, --, --, --, --, --, --, --, --, 2.0, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:libsvm_svc:gamma': masked_array(data=[--, --, --, --, --, --, --, --, --,
0.006276539842771683, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:libsvm_svc:kernel': masked_array(data=[--, --, --, --, --, --, --, --, --, 'poly', --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:libsvm_svc:max_iter': masked_array(data=[--, --, --, --, --, --, --, --, --, -1.0, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:libsvm_svc:shrinking': masked_array(data=[--, --, --, --, --, --, --, --, --, 'False', --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:libsvm_svc:tol': masked_array(data=[--, --, --, --, --, --, --, --, --,
7.288971711473298e-05, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:activation': masked_array(data=[--, --, --, --, --, 'tanh', --, --, --, --, --, 'tanh',
--, --, --, --, --, 'relu', --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:mlp:alpha': masked_array(data=[--, --, --, --, --, 0.00021148999718383549, --, --, --,
--, --, 0.0001363185819149026, --, --, --, --, --,
4.073424522787473e-06, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:batch_size': masked_array(data=[--, --, --, --, --, 'auto', --, --, --, --, --, 'auto',
--, --, --, --, --, 'auto', --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:mlp:beta_1': masked_array(data=[--, --, --, --, --, 0.9, --, --, --, --, --, 0.9, --,
--, --, --, --, 0.9, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:beta_2': masked_array(data=[--, --, --, --, --, 0.999, --, --, --, --, --, 0.999,
--, --, --, --, --, 0.999, --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:early_stopping': masked_array(data=[--, --, --, --, --, 'train', --, --, --, --, --,
'valid', --, --, --, --, --, 'valid', --, --, --, --,
--, --, --, --, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:mlp:epsilon': masked_array(data=[--, --, --, --, --, 1e-08, --, --, --, --, --, 1e-08,
--, --, --, --, --, 1e-08, --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:hidden_layer_depth': masked_array(data=[--, --, --, --, --, 3.0, --, --, --, --, --, 3.0, --,
--, --, --, --, 3.0, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:learning_rate_init': masked_array(data=[--, --, --, --, --, 0.0007452270241186694, --, --, --,
--, --, 0.00018009776276177523, --, --, --, --, --,
0.0059180455768467425, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:n_iter_no_change': masked_array(data=[--, --, --, --, --, 32.0, --, --, --, --, --, 32.0, --,
--, --, --, --, 32.0, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:num_nodes_per_layer': masked_array(data=[--, --, --, --, --, 113.0, --, --, --, --, --, 115.0,
--, --, --, --, --, 27.0, --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:shuffle': masked_array(data=[--, --, --, --, --, 'True', --, --, --, --, --, 'True',
--, --, --, --, --, 'True', --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:mlp:solver': masked_array(data=[--, --, --, --, --, 'adam', --, --, --, --, --, 'adam',
--, --, --, --, --, 'adam', --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:mlp:tol': masked_array(data=[--, --, --, --, --, 0.0001, --, --, --, --, --, 0.0001,
--, --, --, --, --, 0.0001, --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:mlp:validation_fraction': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, 0.1, --,
--, --, --, --, 0.1, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, False, True, True, True, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:multinomial_nb:alpha': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:multinomial_nb:fit_prior': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:passive_aggressive:C': masked_array(data=[--, --, --, --, --, --, --, 0.008807665845919431, --,
--, --, --, --, --, --, --, --, --, --, --, --, 1.0,
--, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:passive_aggressive:average': masked_array(data=[--, --, --, --, --, --, --, 'False', --, --, --, --,
--, --, --, --, --, --, --, --, --, 'True', --, --, --,
--, --, --],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:passive_aggressive:fit_intercept': masked_array(data=[--, --, --, --, --, --, --, 'True', --, --, --, --, --,
--, --, --, --, --, --, --, --, 'True', --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:passive_aggressive:loss': masked_array(data=[--, --, --, --, --, --, --, 'hinge', --, --, --, --,
--, --, --, --, --, --, --, --, --, 'hinge', --, --,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:passive_aggressive:tol': masked_array(data=[--, --, --, --, --, --, --, 0.001174447028725537, --,
--, --, --, --, --, --, --, --, --, --, --, --,
0.00010000000000000009, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True],
fill_value=1e+20),
'param_classifier:qda:reg_param': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:random_forest:bootstrap': masked_array(data=['True', --, --, --, 'True', --, 'True', --, 'False',
--, --, --, --, --, --, --, --, --, --, 'True', --, --,
'False', --, --, 'False', --, 'True'],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value='N/A',
dtype='<U32'),
'param_classifier:random_forest:criterion': masked_array(data=['gini', --, --, --, 'gini', --, 'entropy', --,
'entropy', --, --, --, --, --, --, --, --, --, --,
'entropy', --, --, 'entropy', --, --, 'entropy', --,
'gini'],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value='N/A',
dtype='<U32'),
'param_classifier:random_forest:max_depth': masked_array(data=['None', --, --, --, 'None', --, 'None', --, 'None', --,
--, --, --, --, --, --, --, --, --, 'None', --, --,
'None', --, --, 'None', --, 'None'],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value='N/A',
dtype='<U32'),
'param_classifier:random_forest:max_features': masked_array(data=[0.5, --, --, --, 0.48532133444855097, --,
0.4784709727277252, --, 0.8390317715938469, --, --, --,
--, --, --, --, --, --, --, 0.4678465140755959, --, --,
0.2238485174360173, --, --, 0.663838057151973, --,
0.896406587427711],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value=1e+20),
'param_classifier:random_forest:max_leaf_nodes': masked_array(data=['None', --, --, --, 'None', --, 'None', --, 'None', --,
--, --, --, --, --, --, --, --, --, 'None', --, --,
'None', --, --, 'None', --, 'None'],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value='N/A',
dtype='<U32'),
'param_classifier:random_forest:min_impurity_decrease': masked_array(data=[0.0, --, --, --, 0.0, --, 0.0, --, 0.0, --, --, --, --,
--, --, --, --, --, --, 0.0, --, --, 0.0, --, --, 0.0,
--, 0.0],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value=1e+20),
'param_classifier:random_forest:min_samples_leaf': masked_array(data=[1.0, --, --, --, 1.0, --, 1.0, --, 14.0, --, --, --,
--, --, --, --, --, --, --, 1.0, --, --, 7.0, --, --,
12.0, --, 3.0],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value=1e+20),
'param_classifier:random_forest:min_samples_split': masked_array(data=[2.0, --, --, --, 2.0, --, 14.0, --, 6.0, --, --, --,
--, --, --, --, --, --, --, 2.0, --, --, 15.0, --, --,
11.0, --, 2.0],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value=1e+20),
'param_classifier:random_forest:min_weight_fraction_leaf': masked_array(data=[0.0, --, --, --, 0.0, --, 0.0, --, 0.0, --, --, --, --,
--, --, --, --, --, --, 0.0, --, --, 0.0, --, --, 0.0,
--, 0.0],
mask=[False, True, True, True, False, True, False, True,
False, True, True, True, True, True, True, True,
True, True, True, False, True, True, False, True,
True, False, True, False],
fill_value=1e+20),
'param_classifier:sgd:alpha': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
2.8077187575610757e-05, --, --, --, --, --, --, --, --,
--, --, --, --, 5.21407878915968e-05, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value=1e+20),
'param_classifier:sgd:average': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
'True', --, --, --, --, --, --, --, --, --, --, --, --,
'True', --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:sgd:epsilon': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:sgd:eta0': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:sgd:fit_intercept': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
'True', --, --, --, --, --, --, --, --, --, --, --, --,
'True', --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:sgd:l1_ratio': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
0.275125886570793, --, --, --, --, --, --, --, --, --,
--, --, --, 1.7448730315731382e-06, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value=1e+20),
'param_classifier:sgd:learning_rate': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
'optimal', --, --, --, --, --, --, --, --, --, --, --,
--, 'optimal', --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:sgd:loss': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
'log', --, --, --, --, --, --, --, --, --, --, --, --,
'log', --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:sgd:penalty': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
'elasticnet', --, --, --, --, --, --, --, --, --, --,
--, --, 'elasticnet', --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value='N/A',
dtype='<U32'),
'param_classifier:sgd:power_t': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_classifier:sgd:tol': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --,
1.3351064406792789e-05, --, --, --, --, --, --, --, --,
--, --, --, --, 0.036599115612170205, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, False, True, True,
True, True, True, True, True, True, True, True,
True, True, False, True],
fill_value=1e+20),
'param_data_preprocessor:__choice__': masked_array(data=['feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type', 'feature_type', 'feature_type',
'feature_type'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U12'),
'param_data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': masked_array(data=['one_hot_encoding', 'no_encoding', 'one_hot_encoding',
'one_hot_encoding', 'no_encoding', 'one_hot_encoding',
'no_encoding', 'one_hot_encoding', 'one_hot_encoding',
'one_hot_encoding', 'no_encoding', 'no_encoding',
'no_encoding', 'one_hot_encoding', 'one_hot_encoding',
'no_encoding', 'no_encoding', 'no_encoding',
'one_hot_encoding', 'one_hot_encoding', 'no_encoding',
'no_encoding', 'one_hot_encoding', 'encoding',
'encoding', 'no_encoding', 'one_hot_encoding',
'encoding'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U16'),
'param_data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': masked_array(data=['minority_coalescer', 'minority_coalescer',
'no_coalescense', 'minority_coalescer',
'minority_coalescer', 'no_coalescense',
'no_coalescense', 'minority_coalescer',
'minority_coalescer', 'minority_coalescer',
'minority_coalescer', 'no_coalescense',
'no_coalescense', 'no_coalescense', 'no_coalescense',
'minority_coalescer', 'minority_coalescer',
'minority_coalescer', 'no_coalescense',
'minority_coalescer', 'minority_coalescer',
'minority_coalescer', 'minority_coalescer',
'minority_coalescer', 'minority_coalescer',
'minority_coalescer', 'minority_coalescer',
'no_coalescense'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U18'),
'param_data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': masked_array(data=[0.01, 0.1040851795596776, --, 0.010000000000000004,
0.010000000000000004, --, --, 0.42677247105834165,
0.15465886171097135, 0.010000000000000004,
0.0005589708287942353, --, --, --, --,
0.025659060146568036, 0.41826215858914706,
0.00029426245080363384, --, 0.033371278314588006,
0.3519795567275179, 0.010000000000000004,
0.23197389161862147, 0.09580337973953734,
0.0009919682141534178, 0.24236761074002738,
0.010956288506622502, --],
mask=[False, False, True, False, False, True, True, False,
False, False, False, True, True, True, True, False,
False, False, True, False, False, False, False, False,
False, False, False, True],
fill_value=1e+20),
'param_data_preprocessor:feature_type:numerical_transformer:imputation:strategy': masked_array(data=['mean', 'most_frequent', 'most_frequent',
'most_frequent', 'mean', 'most_frequent',
'most_frequent', 'most_frequent', 'mean', 'median',
'mean', 'median', 'median', 'most_frequent', 'median',
'median', 'median', 'most_frequent', 'mean',
'most_frequent', 'median', 'median', 'mean', 'median',
'mean', 'most_frequent', 'mean', 'median'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U13'),
'param_data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': masked_array(data=['standardize', 'none', 'normalize', 'none', 'minmax',
'standardize', 'none', 'robust_scaler',
'robust_scaler', 'robust_scaler', 'robust_scaler',
'standardize', 'robust_scaler', 'standardize',
'quantile_transformer', 'robust_scaler',
'robust_scaler', 'standardize', 'quantile_transformer',
'quantile_transformer', 'standardize', 'none',
'robust_scaler', 'standardize', 'robust_scaler',
'minmax', 'robust_scaler', 'standardize'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U20'),
'param_data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
1643.0, --, --, --, 654.0, 1000.0, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, True, False, False, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
'uniform', --, --, --, 'uniform', 'uniform', --, --,
--, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, True, False, False, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': masked_array(data=[--, --, --, --, --, --, --, 0.7278293151795671,
0.7083522758919695, 0.75, 0.9803466242807123, --,
0.7633589611863135, --, --, 0.75, 0.7305615609807856,
--, --, --, --, --, 0.7567675243433571, --,
0.9562247541326369, --, 0.881747493735021, --],
mask=[ True, True, True, True, True, True, True, False,
False, False, False, True, False, True, True, False,
False, True, True, True, True, True, False, True,
False, True, False, True],
fill_value=1e+20),
'param_data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': masked_array(data=[--, --, --, --, --, --, --, 0.16271852122755062,
0.26017575741727234, 0.2058549350571071,
0.1005590641662353, --, 0.29630657165502694, --, --,
0.2479524799615851, 0.25595970768123566, --, --, --,
--, --, 0.26248590852108006, --, 0.09878796755160703,
--, 0.011414091334621929, --],
mask=[ True, True, True, True, True, True, True, False,
False, False, False, True, False, True, True, False,
False, True, True, True, True, True, False, True,
False, True, False, True],
fill_value=1e+20),
'param_feature_preprocessor:__choice__': masked_array(data=['no_preprocessing', 'select_rates_classification',
'liblinear_svc_preprocessor',
'select_percentile_classification', 'fast_ica',
'feature_agglomeration', 'select_rates_classification',
'fast_ica', 'select_percentile_classification',
'select_percentile_classification',
'select_rates_classification', 'feature_agglomeration',
'select_rates_classification', 'no_preprocessing',
'extra_trees_preproc_for_classification',
'select_rates_classification', 'polynomial',
'extra_trees_preproc_for_classification', 'polynomial',
'no_preprocessing', 'no_preprocessing',
'select_rates_classification', 'pca',
'select_rates_classification',
'select_rates_classification',
'select_percentile_classification',
'select_percentile_classification',
'select_percentile_classification'],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False],
fill_value='N/A',
dtype='<U38'),
'param_feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
'False', --, --, 'False', --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:extra_trees_preproc_for_classification:criterion': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
'entropy', --, --, 'entropy', --, --, --, --, --, --,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:extra_trees_preproc_for_classification:max_depth': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
'None', --, --, 'None', --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:extra_trees_preproc_for_classification:max_features': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
0.5823188661500757, --, --, 0.3426173612274873, --, --,
--, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
'None', --, --, 'None', --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
0.0, --, --, 0.0, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
15.0, --, --, 14.0, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
5.0, --, --, 10.0, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
0.0, --, --, 0.0, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
100.0, --, --, 100.0, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, False, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:fast_ica:algorithm': masked_array(data=[--, --, --, --, 'parallel', --, --, 'deflation', --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --],
mask=[ True, True, True, True, False, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:fast_ica:fun': masked_array(data=[--, --, --, --, 'cube', --, --, 'exp', --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, False, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:fast_ica:n_components': masked_array(data=[--, --, --, --, --, --, --, 1631.0, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:fast_ica:whiten': masked_array(data=[--, --, --, --, 'False', --, --, 'True', --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --],
mask=[ True, True, True, True, False, True, True, False,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:feature_agglomeration:affinity': masked_array(data=[--, --, --, --, --, 'euclidean', --, --, --, --, --,
'euclidean', --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:feature_agglomeration:linkage': masked_array(data=[--, --, --, --, --, 'complete', --, --, --, --, --,
'ward', --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:feature_agglomeration:n_clusters': masked_array(data=[--, --, --, --, --, 247.0, --, --, --, --, --, 182.0,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:feature_agglomeration:pooling_func': masked_array(data=[--, --, --, --, --, 'max', --, --, --, --, --, 'mean',
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, False, True, True,
True, True, True, False, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:kernel_pca:coef0': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kernel_pca:degree': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kernel_pca:gamma': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kernel_pca:kernel': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kernel_pca:n_components': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kitchen_sinks:gamma': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:kitchen_sinks:n_components': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:liblinear_svc_preprocessor:C': masked_array(data=[--, --, 406.8828992233326, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:liblinear_svc_preprocessor:dual': masked_array(data=[--, --, 'False', --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': masked_array(data=[--, --, 'True', --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': masked_array(data=[--, --, 1.0, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:liblinear_svc_preprocessor:loss': masked_array(data=[--, --, 'squared_hinge', --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:liblinear_svc_preprocessor:multi_class': masked_array(data=[--, --, 'ovr', --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:liblinear_svc_preprocessor:penalty': masked_array(data=[--, --, 'l1', --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:liblinear_svc_preprocessor:tol': masked_array(data=[--, --, 7.92862192773501e-05, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --],
mask=[ True, True, False, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:nystroem_sampler:coef0': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:nystroem_sampler:degree': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:nystroem_sampler:gamma': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:nystroem_sampler:kernel': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:nystroem_sampler:n_components': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:pca:keep_variance': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, 0.9742804373889437, --,
--, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:pca:whiten': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, 'False', --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, False, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:polynomial:degree': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, 2.0, --, 2.0, --, --, --, --, --, --, --, --,
--],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
False, True, False, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:polynomial:include_bias': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, 'True', --, 'True', --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
False, True, False, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:polynomial:interaction_only': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, 'True', --, 'True', --, --, --, --, --, --, --,
--, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
False, True, False, True, True, True, True, True,
True, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:random_trees_embedding:bootstrap': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:max_depth': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:max_leaf_nodes': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:min_samples_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:min_samples_split': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:min_weight_fraction_leaf': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:random_trees_embedding:n_estimators': masked_array(data=[--, --, --, --, --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, True, True, True],
fill_value=1e+20,
dtype=float64),
'param_feature_preprocessor:select_percentile_classification:percentile': masked_array(data=[--, --, --, 93.39844669585806, --, --, --, --,
56.29604107917355, 75.75107575487506, --, --, --, --,
--, --, --, --, --, --, --, --, --, --, --,
75.87523910062363, 16.390084526299404,
91.67664887658442],
mask=[ True, True, True, False, True, True, True, True,
False, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, False, False, False],
fill_value=1e+20),
'param_feature_preprocessor:select_percentile_classification:score_func': masked_array(data=[--, --, --, 'f_classif', --, --, --, --, 'chi2',
'f_classif', --, --, --, --, --, --, --, --, --, --,
--, --, --, --, --, 'mutual_info', 'f_classif',
'f_classif'],
mask=[ True, True, True, False, True, True, True, True,
False, False, True, True, True, True, True, True,
True, True, True, True, True, True, True, True,
True, False, False, False],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:select_rates_classification:alpha': masked_array(data=[--, 0.32118127649740214, --, --, --, --,
0.46621681976184837, --, --, --, 0.14149638953486213,
--, 0.011277906829173396, --, --, 0.3801972898691173,
--, --, --, --, --, 0.058944567903116155, --,
0.3094962987325228, 0.14149638953486213, --, --, --],
mask=[ True, False, True, True, True, True, False, True,
True, True, False, True, False, True, True, False,
True, True, True, True, True, False, True, False,
False, True, True, True],
fill_value=1e+20),
'param_feature_preprocessor:select_rates_classification:mode': masked_array(data=[--, 'fwe', --, --, --, --, 'fpr', --, --, --, 'fwe',
--, 'fdr', --, --, --, --, --, --, --, --, 'fpr', --,
--, 'fwe', --, --, --],
mask=[ True, False, True, True, True, True, False, True,
True, True, False, True, False, True, True, True,
True, True, True, True, True, False, True, True,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'param_feature_preprocessor:select_rates_classification:score_func': masked_array(data=[--, 'chi2', --, --, --, --, 'chi2', --, --, --, 'chi2',
--, 'f_classif', --, --, 'mutual_info_classif', --, --,
--, --, --, 'f_classif', --, 'mutual_info_classif',
'chi2', --, --, --],
mask=[ True, False, True, True, True, True, False, True,
True, True, False, True, False, True, True, False,
True, True, True, True, True, False, True, False,
False, True, True, True],
fill_value='N/A',
dtype='<U32'),
'params': [{'balancing:strategy': 'none',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'True',
'classifier:random_forest:criterion': 'gini',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.5,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 1,
'classifier:random_forest:min_samples_split': 2,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.01,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'no_preprocessing'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'extra_trees',
'classifier:extra_trees:bootstrap': 'True',
'classifier:extra_trees:criterion': 'entropy',
'classifier:extra_trees:max_depth': 'None',
'classifier:extra_trees:max_features': 0.5,
'classifier:extra_trees:max_leaf_nodes': 'None',
'classifier:extra_trees:min_impurity_decrease': 0.0,
'classifier:extra_trees:min_samples_leaf': 1,
'classifier:extra_trees:min_samples_split': 2,
'classifier:extra_trees:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.1040851795596776,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none',
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.32118127649740214,
'feature_preprocessor:select_rates_classification:mode': 'fwe',
'feature_preprocessor:select_rates_classification:score_func': 'chi2'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'extra_trees',
'classifier:extra_trees:bootstrap': 'False',
'classifier:extra_trees:criterion': 'entropy',
'classifier:extra_trees:max_depth': 'None',
'classifier:extra_trees:max_features': 0.7655092431692035,
'classifier:extra_trees:max_leaf_nodes': 'None',
'classifier:extra_trees:min_impurity_decrease': 0.0,
'classifier:extra_trees:min_samples_leaf': 19,
'classifier:extra_trees:min_samples_split': 5,
'classifier:extra_trees:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'normalize',
'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor',
'feature_preprocessor:liblinear_svc_preprocessor:C': 406.8828992233326,
'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False',
'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True',
'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1,
'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge',
'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr',
'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1',
'feature_preprocessor:liblinear_svc_preprocessor:tol': 7.92862192773501e-05},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'gradient_boosting',
'classifier:gradient_boosting:early_stop': 'train',
'classifier:gradient_boosting:l2_regularization': 3.387912939529945e-10,
'classifier:gradient_boosting:learning_rate': 0.30755227194768237,
'classifier:gradient_boosting:loss': 'auto',
'classifier:gradient_boosting:max_bins': 255,
'classifier:gradient_boosting:max_depth': 'None',
'classifier:gradient_boosting:max_leaf_nodes': 60,
'classifier:gradient_boosting:min_samples_leaf': 39,
'classifier:gradient_boosting:n_iter_no_change': 18,
'classifier:gradient_boosting:scoring': 'loss',
'classifier:gradient_boosting:tol': 1e-07,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010000000000000004,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none',
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 93.39844669585806,
'feature_preprocessor:select_percentile_classification:score_func': 'f_classif'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'True',
'classifier:random_forest:criterion': 'gini',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.48532133444855097,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 1,
'classifier:random_forest:min_samples_split': 2,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010000000000000004,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax',
'feature_preprocessor:__choice__': 'fast_ica',
'feature_preprocessor:fast_ica:algorithm': 'parallel',
'feature_preprocessor:fast_ica:fun': 'cube',
'feature_preprocessor:fast_ica:whiten': 'False'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'mlp',
'classifier:mlp:activation': 'tanh',
'classifier:mlp:alpha': 0.00021148999718383549,
'classifier:mlp:batch_size': 'auto',
'classifier:mlp:beta_1': 0.9,
'classifier:mlp:beta_2': 0.999,
'classifier:mlp:early_stopping': 'train',
'classifier:mlp:epsilon': 1e-08,
'classifier:mlp:hidden_layer_depth': 3,
'classifier:mlp:learning_rate_init': 0.0007452270241186694,
'classifier:mlp:n_iter_no_change': 32,
'classifier:mlp:num_nodes_per_layer': 113,
'classifier:mlp:shuffle': 'True',
'classifier:mlp:solver': 'adam',
'classifier:mlp:tol': 0.0001,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'feature_agglomeration',
'feature_preprocessor:feature_agglomeration:affinity': 'euclidean',
'feature_preprocessor:feature_agglomeration:linkage': 'complete',
'feature_preprocessor:feature_agglomeration:n_clusters': 247,
'feature_preprocessor:feature_agglomeration:pooling_func': 'max'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'True',
'classifier:random_forest:criterion': 'entropy',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.4784709727277252,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 1,
'classifier:random_forest:min_samples_split': 14,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none',
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.46621681976184837,
'feature_preprocessor:select_rates_classification:mode': 'fpr',
'feature_preprocessor:select_rates_classification:score_func': 'chi2'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'passive_aggressive',
'classifier:passive_aggressive:C': 0.008807665845919431,
'classifier:passive_aggressive:average': 'False',
'classifier:passive_aggressive:fit_intercept': 'True',
'classifier:passive_aggressive:loss': 'hinge',
'classifier:passive_aggressive:tol': 0.001174447028725537,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.42677247105834165,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7278293151795671,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.16271852122755062,
'feature_preprocessor:__choice__': 'fast_ica',
'feature_preprocessor:fast_ica:algorithm': 'deflation',
'feature_preprocessor:fast_ica:fun': 'exp',
'feature_preprocessor:fast_ica:n_components': 1631,
'feature_preprocessor:fast_ica:whiten': 'True'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'False',
'classifier:random_forest:criterion': 'entropy',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.8390317715938469,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 14,
'classifier:random_forest:min_samples_split': 6,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.15465886171097135,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7083522758919695,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.26017575741727234,
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 56.29604107917355,
'feature_preprocessor:select_percentile_classification:score_func': 'chi2'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'libsvm_svc',
'classifier:libsvm_svc:C': 2176.2897327948685,
'classifier:libsvm_svc:coef0': -0.018575725453357728,
'classifier:libsvm_svc:degree': 2,
'classifier:libsvm_svc:gamma': 0.006276539842771683,
'classifier:libsvm_svc:kernel': 'poly',
'classifier:libsvm_svc:max_iter': -1,
'classifier:libsvm_svc:shrinking': 'False',
'classifier:libsvm_svc:tol': 7.288971711473298e-05,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010000000000000004,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.75,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.2058549350571071,
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 75.75107575487506,
'feature_preprocessor:select_percentile_classification:score_func': 'f_classif'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'gradient_boosting',
'classifier:gradient_boosting:early_stop': 'train',
'classifier:gradient_boosting:l2_regularization': 0.20982857192812085,
'classifier:gradient_boosting:learning_rate': 0.012770531206809599,
'classifier:gradient_boosting:loss': 'auto',
'classifier:gradient_boosting:max_bins': 255,
'classifier:gradient_boosting:max_depth': 'None',
'classifier:gradient_boosting:max_leaf_nodes': 32,
'classifier:gradient_boosting:min_samples_leaf': 69,
'classifier:gradient_boosting:n_iter_no_change': 19,
'classifier:gradient_boosting:scoring': 'loss',
'classifier:gradient_boosting:tol': 1e-07,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.0005589708287942353,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.9803466242807123,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.1005590641662353,
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.14149638953486213,
'feature_preprocessor:select_rates_classification:mode': 'fwe',
'feature_preprocessor:select_rates_classification:score_func': 'chi2'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'mlp',
'classifier:mlp:activation': 'tanh',
'classifier:mlp:alpha': 0.0001363185819149026,
'classifier:mlp:batch_size': 'auto',
'classifier:mlp:beta_1': 0.9,
'classifier:mlp:beta_2': 0.999,
'classifier:mlp:early_stopping': 'valid',
'classifier:mlp:epsilon': 1e-08,
'classifier:mlp:hidden_layer_depth': 3,
'classifier:mlp:learning_rate_init': 0.00018009776276177523,
'classifier:mlp:n_iter_no_change': 32,
'classifier:mlp:num_nodes_per_layer': 115,
'classifier:mlp:shuffle': 'True',
'classifier:mlp:solver': 'adam',
'classifier:mlp:tol': 0.0001,
'classifier:mlp:validation_fraction': 0.1,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'feature_agglomeration',
'feature_preprocessor:feature_agglomeration:affinity': 'euclidean',
'feature_preprocessor:feature_agglomeration:linkage': 'ward',
'feature_preprocessor:feature_agglomeration:n_clusters': 182,
'feature_preprocessor:feature_agglomeration:pooling_func': 'mean'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'gradient_boosting',
'classifier:gradient_boosting:early_stop': 'off',
'classifier:gradient_boosting:l2_regularization': 5.195231690836764e-09,
'classifier:gradient_boosting:learning_rate': 0.06101786517649655,
'classifier:gradient_boosting:loss': 'auto',
'classifier:gradient_boosting:max_bins': 255,
'classifier:gradient_boosting:max_depth': 'None',
'classifier:gradient_boosting:max_leaf_nodes': 10,
'classifier:gradient_boosting:min_samples_leaf': 22,
'classifier:gradient_boosting:scoring': 'loss',
'classifier:gradient_boosting:tol': 1e-07,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7633589611863135,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.29630657165502694,
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.011277906829173396,
'feature_preprocessor:select_rates_classification:mode': 'fdr',
'feature_preprocessor:select_rates_classification:score_func': 'f_classif'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'sgd',
'classifier:sgd:alpha': 2.8077187575610757e-05,
'classifier:sgd:average': 'True',
'classifier:sgd:fit_intercept': 'True',
'classifier:sgd:l1_ratio': 0.275125886570793,
'classifier:sgd:learning_rate': 'optimal',
'classifier:sgd:loss': 'log',
'classifier:sgd:penalty': 'elasticnet',
'classifier:sgd:tol': 1.3351064406792789e-05,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'no_preprocessing'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'extra_trees',
'classifier:extra_trees:bootstrap': 'True',
'classifier:extra_trees:criterion': 'entropy',
'classifier:extra_trees:max_depth': 'None',
'classifier:extra_trees:max_features': 0.15687109796165688,
'classifier:extra_trees:max_leaf_nodes': 'None',
'classifier:extra_trees:min_impurity_decrease': 0.0,
'classifier:extra_trees:min_samples_leaf': 3,
'classifier:extra_trees:min_samples_split': 13,
'classifier:extra_trees:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer',
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 1643,
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform',
'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification',
'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'False',
'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'entropy',
'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None',
'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.5823188661500757,
'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None',
'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0,
'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 15,
'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 5,
'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0,
'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'lda',
'classifier:lda:shrinkage': 'auto',
'classifier:lda:tol': 0.06502391592449622,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.025659060146568036,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.75,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.2479524799615851,
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.3801972898691173,
'feature_preprocessor:select_rates_classification:score_func': 'mutual_info_classif'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'extra_trees',
'classifier:extra_trees:bootstrap': 'False',
'classifier:extra_trees:criterion': 'entropy',
'classifier:extra_trees:max_depth': 'None',
'classifier:extra_trees:max_features': 0.993803313878608,
'classifier:extra_trees:max_leaf_nodes': 'None',
'classifier:extra_trees:min_impurity_decrease': 0.0,
'classifier:extra_trees:min_samples_leaf': 2,
'classifier:extra_trees:min_samples_split': 20,
'classifier:extra_trees:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.41826215858914706,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7305615609807856,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.25595970768123566,
'feature_preprocessor:__choice__': 'polynomial',
'feature_preprocessor:polynomial:degree': 2,
'feature_preprocessor:polynomial:include_bias': 'True',
'feature_preprocessor:polynomial:interaction_only': 'True'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'mlp',
'classifier:mlp:activation': 'relu',
'classifier:mlp:alpha': 4.073424522787473e-06,
'classifier:mlp:batch_size': 'auto',
'classifier:mlp:beta_1': 0.9,
'classifier:mlp:beta_2': 0.999,
'classifier:mlp:early_stopping': 'valid',
'classifier:mlp:epsilon': 1e-08,
'classifier:mlp:hidden_layer_depth': 3,
'classifier:mlp:learning_rate_init': 0.0059180455768467425,
'classifier:mlp:n_iter_no_change': 32,
'classifier:mlp:num_nodes_per_layer': 27,
'classifier:mlp:shuffle': 'True',
'classifier:mlp:solver': 'adam',
'classifier:mlp:tol': 0.0001,
'classifier:mlp:validation_fraction': 0.1,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.00029426245080363384,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification',
'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'False',
'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'entropy',
'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None',
'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.3426173612274873,
'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None',
'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0,
'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 14,
'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 10,
'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0,
'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'gradient_boosting',
'classifier:gradient_boosting:early_stop': 'train',
'classifier:gradient_boosting:l2_regularization': 0.05488841601458162,
'classifier:gradient_boosting:learning_rate': 0.0843846716858782,
'classifier:gradient_boosting:loss': 'auto',
'classifier:gradient_boosting:max_bins': 255,
'classifier:gradient_boosting:max_depth': 'None',
'classifier:gradient_boosting:max_leaf_nodes': 4,
'classifier:gradient_boosting:min_samples_leaf': 3,
'classifier:gradient_boosting:n_iter_no_change': 16,
'classifier:gradient_boosting:scoring': 'loss',
'classifier:gradient_boosting:tol': 1e-07,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer',
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 654,
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform',
'feature_preprocessor:__choice__': 'polynomial',
'feature_preprocessor:polynomial:degree': 2,
'feature_preprocessor:polynomial:include_bias': 'True',
'feature_preprocessor:polynomial:interaction_only': 'True'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'True',
'classifier:random_forest:criterion': 'entropy',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.4678465140755959,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 1,
'classifier:random_forest:min_samples_split': 2,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.033371278314588006,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer',
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 1000,
'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform',
'feature_preprocessor:__choice__': 'no_preprocessing'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'adaboost',
'classifier:adaboost:algorithm': 'SAMME',
'classifier:adaboost:learning_rate': 0.2844845910527844,
'classifier:adaboost:max_depth': 2,
'classifier:adaboost:n_estimators': 370,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.3519795567275179,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'no_preprocessing'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'passive_aggressive',
'classifier:passive_aggressive:C': 1.0,
'classifier:passive_aggressive:average': 'True',
'classifier:passive_aggressive:fit_intercept': 'True',
'classifier:passive_aggressive:loss': 'hinge',
'classifier:passive_aggressive:tol': 0.00010000000000000009,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010000000000000004,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none',
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.058944567903116155,
'feature_preprocessor:select_rates_classification:mode': 'fpr',
'feature_preprocessor:select_rates_classification:score_func': 'f_classif'},
{'balancing:strategy': 'none',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'False',
'classifier:random_forest:criterion': 'entropy',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.2238485174360173,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 7,
'classifier:random_forest:min_samples_split': 15,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.23197389161862147,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7567675243433571,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.26248590852108006,
'feature_preprocessor:__choice__': 'pca',
'feature_preprocessor:pca:keep_variance': 0.9742804373889437,
'feature_preprocessor:pca:whiten': 'False'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'bernoulli_nb',
'classifier:bernoulli_nb:alpha': 39.87397441278958,
'classifier:bernoulli_nb:fit_prior': 'False',
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.09580337973953734,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.3094962987325228,
'feature_preprocessor:select_rates_classification:score_func': 'mutual_info_classif'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'gradient_boosting',
'classifier:gradient_boosting:early_stop': 'train',
'classifier:gradient_boosting:l2_regularization': 0.22864775632104425,
'classifier:gradient_boosting:learning_rate': 0.012770531206809599,
'classifier:gradient_boosting:loss': 'auto',
'classifier:gradient_boosting:max_bins': 255,
'classifier:gradient_boosting:max_depth': 'None',
'classifier:gradient_boosting:max_leaf_nodes': 41,
'classifier:gradient_boosting:min_samples_leaf': 55,
'classifier:gradient_boosting:n_iter_no_change': 10,
'classifier:gradient_boosting:scoring': 'loss',
'classifier:gradient_boosting:tol': 1e-07,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.0009919682141534178,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.9562247541326369,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.09878796755160703,
'feature_preprocessor:__choice__': 'select_rates_classification',
'feature_preprocessor:select_rates_classification:alpha': 0.14149638953486213,
'feature_preprocessor:select_rates_classification:mode': 'fwe',
'feature_preprocessor:select_rates_classification:score_func': 'chi2'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'False',
'classifier:random_forest:criterion': 'entropy',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.663838057151973,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 12,
'classifier:random_forest:min_samples_split': 11,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'no_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.24236761074002738,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax',
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 75.87523910062363,
'feature_preprocessor:select_percentile_classification:score_func': 'mutual_info'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'sgd',
'classifier:sgd:alpha': 5.21407878915968e-05,
'classifier:sgd:average': 'True',
'classifier:sgd:fit_intercept': 'True',
'classifier:sgd:l1_ratio': 1.7448730315731382e-06,
'classifier:sgd:learning_rate': 'optimal',
'classifier:sgd:loss': 'log',
'classifier:sgd:penalty': 'elasticnet',
'classifier:sgd:tol': 0.036599115612170205,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.010956288506622502,
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler',
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.881747493735021,
'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.011414091334621929,
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 16.390084526299404,
'feature_preprocessor:select_percentile_classification:score_func': 'f_classif'},
{'balancing:strategy': 'weighting',
'classifier:__choice__': 'random_forest',
'classifier:random_forest:bootstrap': 'True',
'classifier:random_forest:criterion': 'gini',
'classifier:random_forest:max_depth': 'None',
'classifier:random_forest:max_features': 0.896406587427711,
'classifier:random_forest:max_leaf_nodes': 'None',
'classifier:random_forest:min_impurity_decrease': 0.0,
'classifier:random_forest:min_samples_leaf': 3,
'classifier:random_forest:min_samples_split': 2,
'classifier:random_forest:min_weight_fraction_leaf': 0.0,
'data_preprocessor:__choice__': 'feature_type',
'data_preprocessor:feature_type:categorical_transformer:categorical_encoding:__choice__': 'encoding',
'data_preprocessor:feature_type:categorical_transformer:category_coalescence:__choice__': 'no_coalescense',
'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median',
'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize',
'feature_preprocessor:__choice__': 'select_percentile_classification',
'feature_preprocessor:select_percentile_classification:percentile': 91.67664887658442,
'feature_preprocessor:select_percentile_classification:score_func': 'f_classif'}],
'rank_test_precision': array([ 3, 6, 21, 10, 16, 2, 4, 23, 12, 25, 15, 9, 14, 7, 5, 25, 19,
18, 11, 1, 20, 25, 22, 25, 13, 17, 24, 8]),
'rank_test_recall': array([16, 14, 8, 11, 22, 12, 16, 23, 2, 25, 3, 20, 6, 12, 24, 25, 15,
19, 7, 16, 4, 25, 21, 25, 1, 4, 10, 9]),
'status': ['Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Timeout',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success',
'Success']}
Visualize the Pareto set¶
plot_values = []
pareto_front = automl.get_pareto_set()
for ensemble in pareto_front:
predictions = ensemble.predict(X_test)
precision = sklearn.metrics.precision_score(y_test, predictions)
recall = sklearn.metrics.recall_score(y_test, predictions)
plot_values.append((precision, recall))
fig = plt.figure()
ax = fig.add_subplot(111)
for precision, recall in plot_values:
ax.scatter(precision, recall, c="blue")
ax.set_xlabel("Precision")
ax.set_ylabel("Recall")
ax.set_title("Pareto set")
plt.show()
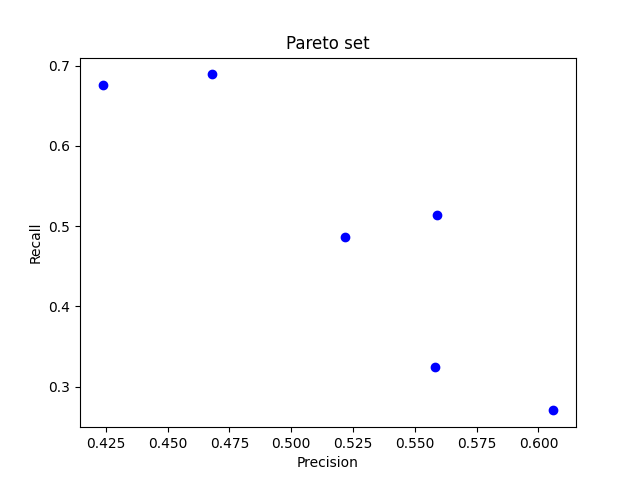
Total running time of the script: ( 2 minutes 12.970 seconds)